
SuttaCentral
SuttaCentral contains early Buddhist texts, known as the Tipiṭaka or “Three Baskets”. This is a large collection of teachings attributed to the Buddha or his earliest disciples, who were teaching in India around 2500 years ago. They are regarded as sacred canon in all schools of Buddhism.
There are several Buddhist traditions, and each has passed down a set of scriptures from ancient times. SuttaCentral is specially focused on the scriptures of the earliest period of Buddhism, and hosts texts in over thirty languages. We believe this is the largest collection of early Buddhist texts ever made.
SuttaCentral hosts the texts in orginal languages, translations in modern languages, and extensive sets of parallels that show the relationship between them all.
Bilara
To support the ongoing improvement of Buddhist translations, SuttaCentral has developed the Computer Assisted Translation (CAT) system called Bilara (which means “cat” in Pali).
Bilara is an open-source project using Github as storage and version control. It includes:
- a structured data system for managing texts and translations in many languages, as well as associated metadata.
- a webapp for translators, which includes translation memory suggestions, advanced search capabilties, and customizable interface.
- a pipeline to bring texts to publication with accurate and detailed publication metadata.
Bilara data
The content for Bilara is maintained in JSON files. Unlike traditional markup systems, which mix text, markup, and metadata, Bilara utilizes standoff markup.
To translate a text in Bilara, it must first be segmented, that is, divided into short, translatable (and hence meaningful) segments of text, typically a sentence, a heading, or a line of verse.
Once segmented, each kind of data is divided into separate files as JSON key/value pairs, and they are coordinated with matching ID numbers. Then the content can be mix-and-matched at will. SuttaCentral provides the Bilara i/o utility for this purpose; it exports any desired Bilara data into a speadsheet or other file form.
Here’s a simple example. This is the text for SN 1.44.
"sn1.44:1.1": "“Ekamūlaṁ dvirāvaṭṭaṁ, ",
"sn1.44:1.2": "timalaṁ pañcapattharaṁ; ",
"sn1.44:1.3": "Samuddaṁ dvādasāvaṭṭaṁ, ",
"sn1.44:1.4": "pātālaṁ atarī isī”ti. "
Here is the corresponding English translation.
"sn1.44:1.1": "“One is the root, two are the whirlpools, ",
"sn1.44:1.2": "three are the stains, five the spreads, ",
"sn1.44:1.3": "twelve the ocean’s whirlpools: ",
"sn1.44:1.4": "such is the abyss crossed over by the hermit.”"
Translations can be made in as many languages as we like. Here is a Portuguese translation.
"sn1.44:1.1": "“Uma raíz, dois redemoinhos,",
"sn1.44:1.2": "três impurezas, cinco extensões,",
"sn1.44:1.3": "o oceano com os seus doze redemoinhos:",
"sn1.44:1.4": "assim é o abismo atravessado pelo eremita.”"
HTML markup is kept separately, and may be applied to any text or translation.
"sn1.44:1.1": "<blockquote class='gatha'><p><span class='verse-line'>{}</span>",
"sn1.44:1.2": "<span class='verse-line'>{}</span>",
"sn1.44:1.3": "<span class='verse-line'>{}</span>",
"sn1.44:1.4": "<span class='verse-line'>{}</span></p></blockquote></article>"
References are maintained in another separate file.
"sn1.44:1.1": "ms12S1_249, msdiv44"
Any other form of metadata can also be kept in the same form. For example comments:
"sn1.44:1.3": "This is not a real comment, I just wanted to give a sample!"
Variant readings have their own special markup.
"dvirāvaṭṭaṁ": "dvirāvaṭṭaṁ → dvi āvaṭṭaṁ (vri)"
Bilara webapp
Normally translators won’t have to worry about data forms, they can just translate directly in the Bilara webapp.
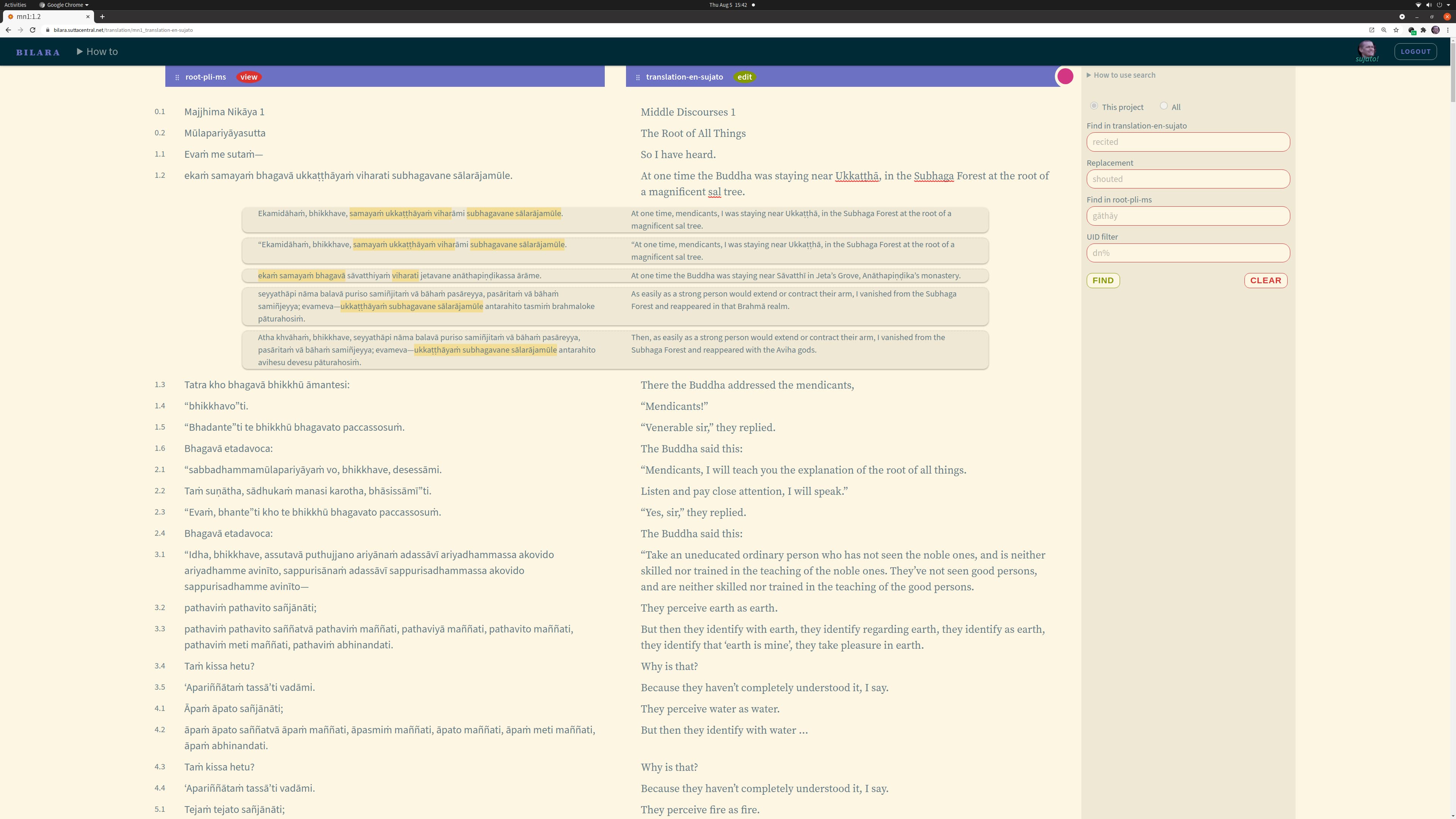
The webapp provides a clean interface optimized for translation of texts. Typically there is a column for the root text and the translation; the app suggests translations based on previous translations. Translators can customixe the interface, changing order of columns, adding more columns for notes or translations in other languages, for example.
Bilara Publication workflow
Once the translator has completed their work, they simply hit “publish” and this will signal that the work is ready to publish. The work will be moved from the “unpublished” to “published” branch on Github, and is then ready to be consumed by apps.
Normally a published text is automatically added to SuttaCentral. However it is not limited to that, anyone can build an app using the published data. For example, the SuttaCentral Voice app consumes Bilara data to create audio for those who want to listen to Suttas. Buddhanexus consumes Bilara data to inform its AI models of Buddhist texts. Others have used the data for printing books, or creating EPUBs.
By using one simple, standardized data form, and keeping everything open and unencumbered by licenses, the potential uses of our work have an impact that we could not have imagined.